PULP-TrainLib: Enabling On-Device Training for RISC-V Multi-Core MCUs through Performance-Driven Autotuning
Reading it from here.
Abstract
Problem:
Making Internet-of-Things (IoT) sensor nodes "smart" and "self-adaptive" requires enabling on-chip Deep Neural Network (DNN) training on Ultra-Low-Power (ULP) Microcontroller Units (MCUs). This is challenging. So ideally if we have a chip that can do this, it would be nice.
Solution:
- A library of parallel software DNN primitives( matrix mul , add , dot, transpose, etc) for training on RISC-V-based Parallel-ULP (PULP) MCUs. It handles both forward and backward steps of training. Basically these primitives are what installed in Nvidia GPUs and stuff as well — which is optimized for their specific hardware. So this is a similar idea but for RISC-V MCUs.
To optimize PULP-TrainLib’s kernels, we propose a strategy to automatically select and configure (autotune) the fastest among a set of tiling options and optimized floating-point matrix multiplication kernels, according to the tensor shapes of every DNN layer.
- Some autotuning strategy, I don't get this bruh. But here are some terms which does make sense:
- Tiling: Breaking up large tensors into smaller chunks – tiles, so they can fit in the small memory , let's say L1 cache and get processed efficiently.
- Floating-Point Matrix: Different implementation of matmul , ig some optimization strategies are imposed to have variable trade-offs between speed and accuracy.
- Autotune: Automatically selecting the best configuration for the above based on the specific tensor shapes of each DNN layer.
Results:
- Autotuned primitives improve MAC/clk (Multiply-Accumulate operations per clock cycle, a measure of computational efficiency) by up to 2.4x compared to a generic "one-size-fits-all" approach.
- Achieves up to 4.39 MAC/clk, which is 36.6x better than a commercial STM32L4 MCU on the same task.
- The strategy is 30.7x faster than AIfES (a state-of-the-art training library for MCUs) when training a complete TinyML model.
Intro
Current Design:
- Train the DNN on powerful GPU servers and then deploy it to edge platforms for inference only.
- It's kinda static, but it words, it doesn't have the ability to adapt by itself which is concerning.
Newer Methods:
- Transfer Learning: Adapting a pre-trained model to a new, related task with less data.
- Continual Learning: Learning sequentially from new data without forgetting previously learned knowledge.
- Incremental Learning: Gradually updating the model with new data.
- So ALLLL of them use , drum roll please — Backpropagation (the algorithm for calculating gradients) and Stochastic Gradient Descent (SGD) (the optimization algorithm to update model weights).
Challenges of Deploying Training Algos on MCUs:
- Needs forward and backward propagation (unlike inference which is only forward).
- Floating-point operations are more expensive on MCUs than quantized (e.g., 8-bit integer) operations common in edge inference.
- SGD needs many passes over the data (epochs/iterations) to converge, whereas inference is often a single pass.
- Single element processing: MCUs often process data one element at a time, limiting parallelism from batching.
Paper's Approach on Solving the issues:
- Use PULP (Parallel Ultra-Low Power ) devices —muti-core MCUs designed for high performance and low power at edge.
- Ref Paper for above:Neuro Zero
- PULP-TrainLib: A DNN training software library for RISC-V-based multi-core PULP devices, providing latency-optimized, tunable forward and backward training primitives. ( basically pytorch but for RISC-V MCUs)
- Couples ple PULP-TrainLib with AutoTuner: An automated tool to select the fastest configuration (MM kernel and tiling) for each DNN layer, optimizing performance based on the specific tensor shapes. ( this is almost what the gist of the paper is about, the autotuning part — I think that i guess)
- PULP-Train is open source – available on GitHub.
Related Work
- I skipped this 😭.
On Device Training on PULP
PULP Platform:
- PULP SoC : A computational platform for energy-efficient, scalable edge computing using RISC-V cores.
The MCU features a single RISC-V core, a set of IO peripherals, and a 2 MB SRAM memory (L2) accessible by the cluster side through a DMA engine. The cluster includes 8 RISC-V cores sharing a 64 kB L1 memory, accessible in a single cycle. Each core implements a basic set of standard RISC-V extensions (RV32IMFC); additionally, a custom extension (Xpulp) provides DSP-like features to reduce overhead in highly uniform workloads, including post-increment load/store operations and 2-level nested hardware loops. Finally, each CPU is granted access to a private Floating Point Unit (FPU), capable of performing complex, single-cycle DSP instructions, like Fused Multiply-Add (FMA).
- *Krish notices lots of big words, tempting to make a joke right now
- So this was basically their GPU, or the processor that they were running the experiments on , interesting to note that PULP-TrainLib is —"the first" library for training DNNs on RISC-V MCUs, which is a big deal.
PULP-TrainLib Library:
-
Provides optimized software for forward and backward propagation of DNN layers on PULP, using floating-point data formats (fp32).
-
X : Input tensor.
-
W: Trainable weights.
-
Y: Output tensor.
-
FW (Forward): Computes
YfromXandW. -
Intermediate tensors from FW pass are stored for the BW pass.
-
dY: Gradient of the loss with respect to the output
Y. -
dW (Weight Gradient): Computed by WG-BW (Weight Gradient Backward) using
XanddY. -
dX (Input Gradient): Computed by IG-BW (Input Gradient Backward) using
dYand transposed weightsW'. ThisdXbecomes thedYfor the previous layer.
So those are interesting words: WG-BW and IG-BW which are the weight gradient backward and input gradient backward respectively, which are used to compute the gradients for the weights and inputs during backpropagation.
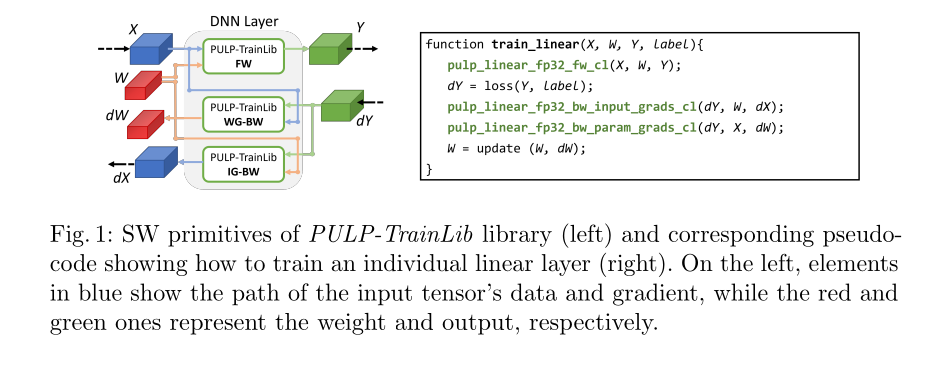
- The Above Figure 1 shows us the computational flow of the PULP-TrainLib library, with the forward and backward passes for a linear layer.
- Shows how PULP-TrainLib primitives are called:
pulp_linear_fp32_fw_cl(forward),loss(calculate dY),pulp_linear_fp32_bw_input_grads_cl(IG-BW),pulp_linear_fp32_bw_param_grads_cl(WG-BW),update(update W using dW).
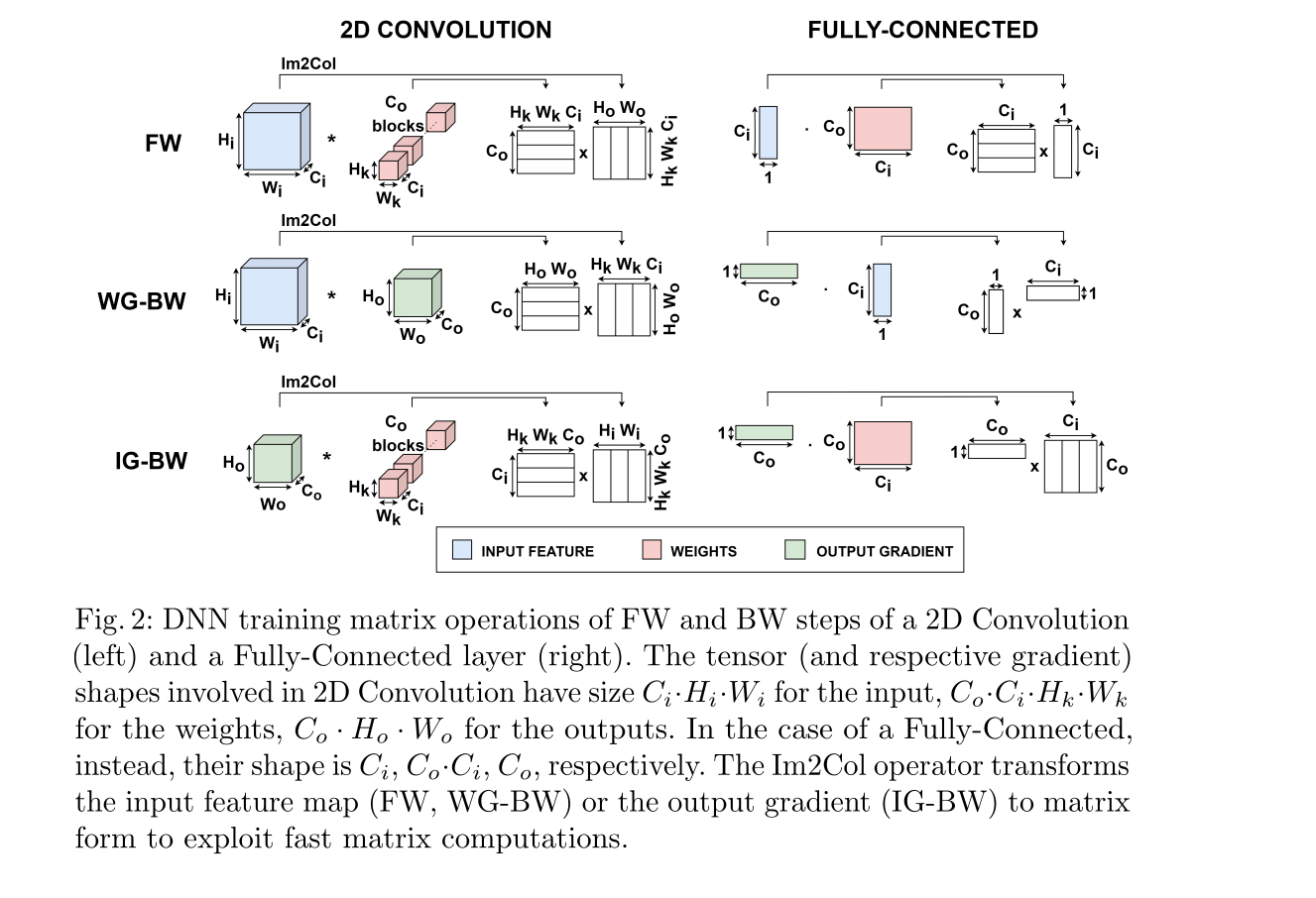
- The Above Figure 2 shows how 2D Convolution and Fully-Connected layer operations are primarily Matrix Multiplications (MMs).
- Im2Col: Image to Column — A transformation used in convolutions. It unnests patches of the input feature map (or output gradient for IG-BW) and arranges them as columns in a new matrix. This allows the convolution to be performed as a standard MM, which can be highly optimized. The paper notes this transformation is done at runtime into L1 memory.
- Tenshor shapes are defined:
Ci Hi Wi(Input Channels, Height, Width),Co Ci Hk Wk(Output Channels, Input Channels, Kernel Height, Kernel Width), etc. ( vv similar to pytorch)
PULP-TrainLib Primitives and AutoTuner
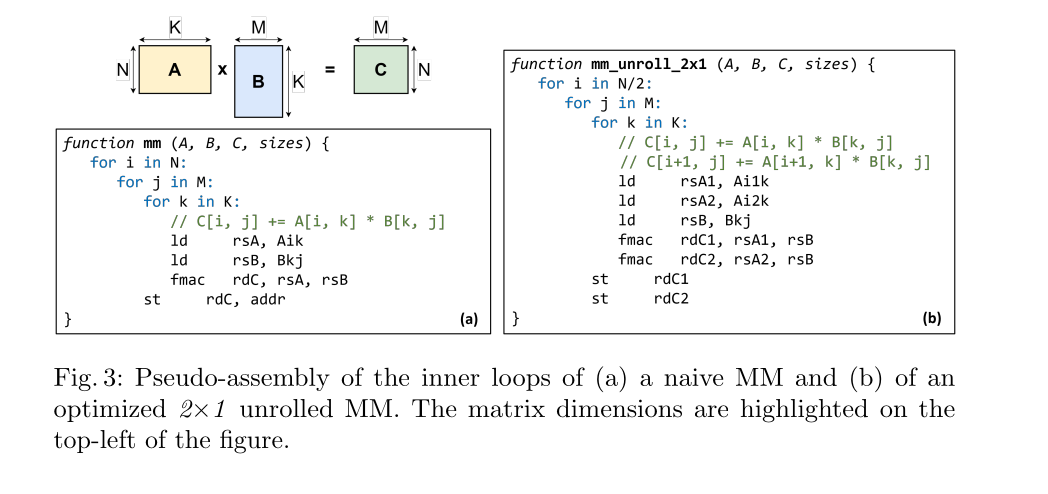
- (3a) Idk why the authors just kept the naive implementation of the MM in the paper, but it is what it is. 😭 Just to tell us it takes
instructions.
Loop Unrolling:
< i am yet to understand this >
- A technique to reduce loop overhead and increase instruction-level parallelism by computing multiple outputs within the inner loop, improving data reuse.
- (3b) Shows an example of a 2x1 unrolled MM, which computes two elements of the output matrix
Cper inner loop iteration, improving the FMA/Load ratio. - FMA: Fused Multiply-Add, a single instruction that performs multiplication and addition in one step, reducing latency.
The total number of instructions can be reduced by means of loop unrolling. This technique leads to a faster implementation by computing multiple outputs within the inner loop, hence exploiting data reuse. As a convention, we define the unrolling factor as U × V, where U and V are, respectively, the number of rows and columns of the output matrix concurrently computed within the inner loop of the MM. In particular, Figure 3 (b) represents a 2×1 loop unrolling, which features a 33% higher FMA/Load ratio with respect to the naı̈ve baseline, therefore reducing the overall number of instructions.
< will come back here again >
TODO: finish learning Loop Unrolling:
AutoTuner:
- A tool to automatically select the best MM kernel and tiling configuration for each DNN layer based on the specific tensor shapes and PULP platform settings.
- It is ran offline before training , fastest software is identified, then deployed on target device.
- The authors goes on explain why Tiling is needed in MCUs. Simplest answer is the input output tensors just don't fit in L1 memory, so they are partitioned into smaller sub-tensors known as Tensor Tiles. L2->L1 , then processed sequentially.
im2colis performed in L1 for each tile. - im2col: (Image to Column )is a transformation that reshapes the input tensor for convolution operations, allowing it to be treated as a matrix multiplication problem.
Algogorithm 1 (AutoTuner for PULP-TrainLib):

- Input: L1 memory size, number of cores, DNN layer info, tensor shapes, and a table of MM kernels.
- Output: The best MM kernel and tile shape configuration.
: Maximum number of tiling solutions to evaluate on hardware.
Function Tiler(L1MemSize, T)
- Computes possible tiling solutions for the given tensor shapes.
- Removes those who are greater than L1 memory.
- Sorts them by Memory Usage.
- Returns the top
largest feasible tensor shapes (tiles).
AutoTuner Logic:
- If the original tensor shape fits in L1 memory, use it directly (single entry for
TensorList). - Else, call
Tilerto get a list of feasible tensor shapes (tiles). - For each tensor shape in
TensorList:- For each MM kernel in the table:
- Simulate the DNN training layer with the current MM kernel, tensor shape (tile), and number of cores using GVSOC (a behavioral event-based MCU simulator for PULP, claimed to have <5% error).
- Store
{Latency, TensorShape, MM}inPerfLog.
- For each MM kernel in the table:
- Return the MM kernel and tile shape from
PerfLogthat has the lowest latency.
- The AutoTuner performs a grid search over the tiling solutions and MM kernels, evaluating each configuration's latency on the hardware simulator.
GVSOC is it's own different ballgame now.
