K-means
K-means in a nutshell:
assign points
Both can come from optimizing a single objective function:
Binary indicator:
Basically
Finding
Of course, the next step is to update
Enough of intuition lad, Here's your mathematical jargon:
For the fixed
Literally just the mean of all the points belonging to cluster
Q&A
Q: Why initialize centres first?
A: If not done otherwise, i.e., using random centers to all points, makes it so that no points at all.
On an unlucky assignment of centre this can happen too but very rarely either ways we will have closest cluster to any data point while the assignment step and algorithm keeps going.
E-step
M-step
But this E-M step lead to local minima. We do random start on
K++
Pick first centre randomly.
Then we have
What this essentially does is that it favours points which are far away from already chosen centres making it more likely to pick a centre in a new cluster.
Use Cases
Lossy Compression
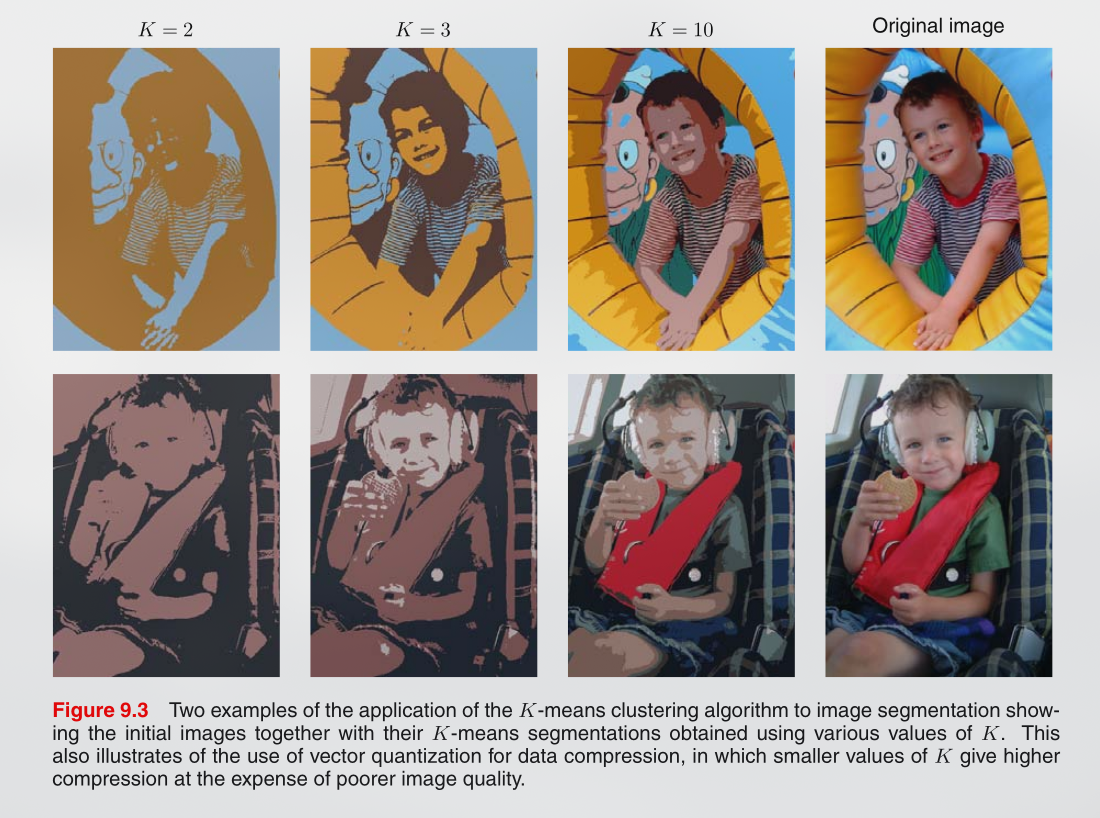
Image taken from Pattern Recognition and Machine Learning
We apply K-means in the following manner:
For each N data points, we only story the identity of k of the cluster to which it is assigned.
You also store the value of the K cluster-centres
It's called a vector quantization framework.
Example for Image segmentation:
For an image
Figure:
So in our case of {R,G,B} with 8 bit precision we would need
Now suppose we first run K-means on the image data, and then instead of transmitting the original pixel intensity vectors we transmit the identity of the nearest vector
Medoid
Medoid: (not mean, an actual point in the dataset)
when
Limitations
- Assumes spherical clusters
- Hard assignments
- Sensitive to outliers
To kind of tackle this we use Mixture Models.