GLMs are here babby!!!.
We need to understand more about exponential family distributions before we get into GLMs.
Where all of the terms are:
is data. is natural parameter. is called sufficient statistics. is base measure. is log-partition.
Quick observation tells us that these functions are only of certain parameters, so T(y) is a function only and only of y and not
Some of the common exponential as these functions are:
Bernoulli:
Gaussian with variance = 1:
Overview of GLMs:


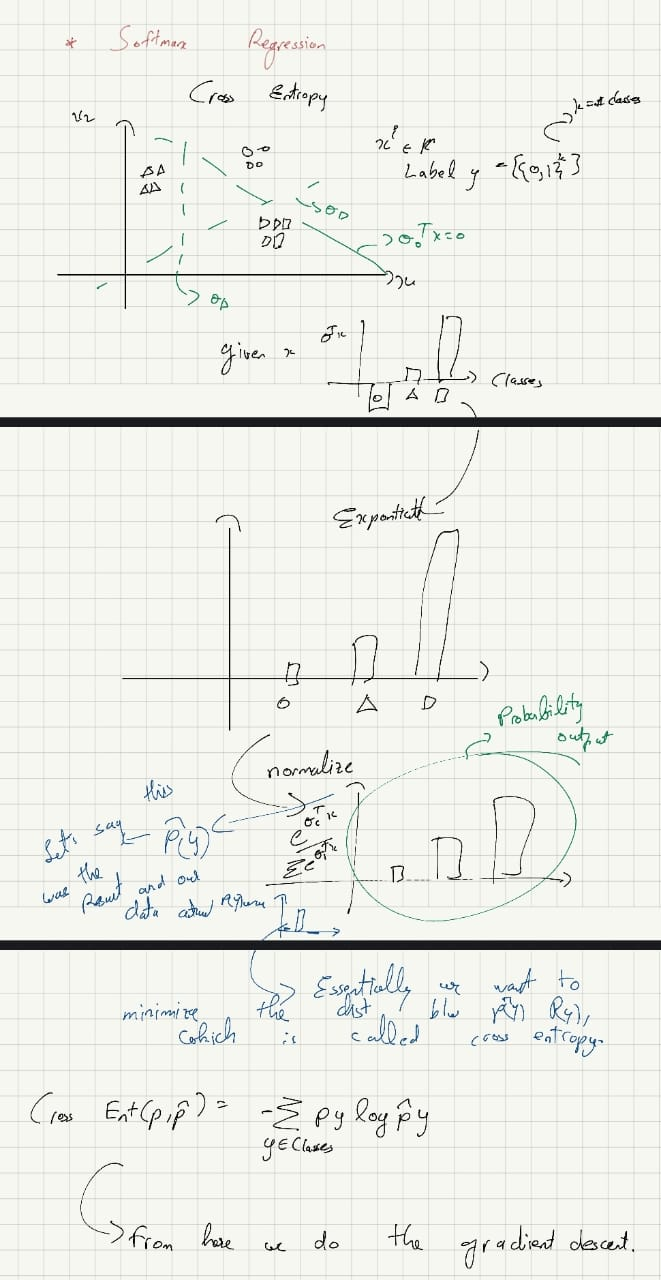
Softmax Regression:
In a broader case, we can have multiple classes instead of the binary classes above. It is natural to model it as a Multinomial distribution, which also belongs to the exponential family that can be derived from the Generalized Linear Model (GLM).
In multinomial, we can define
We first define
Note that for
Now, we show the steps to derive the Multinomial distribution as an exponential family:
where
and
This formulates the multinomial distribution as an exponential family. We can now have the link function as:
To get the response function, we need to invert the link function:
Then, we have the response function:
This response function is called the softmax function.
From the assumption (3) in GLM, we know that
This model is called softmax regression, which is a generalization of logistic regression. Thus, the hypothesis will be:
Now, we need to fit
We can use gradient descent or Newton’s method to find the maximum of it.
Note: Logistic regression is a binary case of softmax regression. The sigmoid function is a binary case of the softmax function.
Overview simplified: