My Notes:
- Pre-Training
- Tokenization
- Training the Model
- Visualizing an LLM
- Inferences
- GPT-2
- [The Original Paper](#the-original-paperhttpscdnopenaicombetter-language-modelslanguagemodelsareunsupervisedmultitasklearnerspdf)
- Base Model
- Post-Training
- [InstructGPT ( Original Paper )](#instructgpt-original-paperhttpsarxivorgpdf220302155)
- Hallucinations , Memory , Awareness
- Transformer related Stuff
- Sources:
Pre-Training
- Download and preprocess the data.
Tokenization
- Process of converting text(string) into tokens (integers).
Naive Approaches
- Using word level or character level mapping using LUTs.
Problems with this approach
- Word level:
- Vocabulary size is huge.
- Out of vocabulary words.
- Rare words are not handled well.
- Character level:
- Too many tokens.
- Long sequences.
- Doesn't capture semantics.
- Doesn't account for other languages.
Byte Pair Encoding
- Iteratively replaces the most common pair of consecutive tokens with a new token.
- This allows the model to learn sub-word units and handle out-of-vocabulary words more effectively.
For example, the word "unhappiness" might be tokenized as "un", "happi", and "ness". - This is a greedy algorithm and is not optimal ( but it is used in practice).
- The way I understand this handles out of vocabulary words and rare words well is because we humans also kind of do the same, suffix-prefix and relational understanding is captured in this kinda.
Training the Model
- Training the neural net to adjust it to get the predictions as the stats from training sets.
Visualizing an LLM
- These are transformer architecture visualizations.
Inferences
- The process of using the trained model to make predictions on new data.
- Iteratively keep predicting the next token until we reach the end of sentence token or stopping criteria is met.
GPT-2
The Original Paper
- The original paper that introduced the GPT-2 model.
- It was based on transformer architecture and it has 1.6B parameters.
- Context length was 1024 tokens.
- Trained on 100 B tokens.
- Current SOTA models are around 500~700B parameters for CoT, (DeepSeek-R1 is 670B). ( Gemini output token size is 64k, insane scaling man)
Base Model
- Token level trained dataset simulator.
- Probabilistic model that predicts the next token given the previous tokens.
- Regurigation: will recite some stuff from what it remembers from training.
- Will need few shot prompting ( and from this using it's in-context understanding) it might act like an assistant.
Post-Training
InstructGPT ( Original Paper )
- 68 page paper 🛐.
- Basically taught us how to actually make InstructGPT, by creating a dataset of human feedback.
- Trained the model to follow instructions and be more helpful. Like remove toxic features by including those examples and teaching the model to say no.
Open Source Datasets Visualization ( This visualization is of UltraChat, it's popular but now that Models became good it is mostly synthetic data. )
Hallucinations , Memory , Awareness
How to reduce hallucinations?
- People figured out that we can add examples in the dataset like I don't know the answer to that or I am not sure about that.
- Now how do we even figure this out? -> You Generate Synthetic Questions using powerful Models, ask them multiple times, answer changes/gets it wrong, you add an example in the instruct to say it doesn't know.
- So After this process of adding multiple instructions, model learns that when it is not sure it should say it doesn't know.
- We also teach to use tools like web search using special tokens.
Memory
!!! "Vague recollection" vs. "Working memory" !!!
- Knowledge in the parameters == Vague recollection (e.g. of something you read 1 month ago)
- Knowledge in the tokens of the context window == Working memory
Knowledge of Self
- Can be given as the "SYSTEM_PROMPT".
- Basically by itself the model doesn't know what it is, so highly probably is that it would spit / hallucinate that I am developed by openAI or something like that , that doesn't mean that someone stole openAI's model and used it, or their data, it's just generating the most probable answer it knows.
Post-Training
SFT ( Supervised Fine Tuning )
- So all these stuff we discussed above is basically about hallucinations and adding instruct datasets, it's supervised fine tuning.
- It teaches how to follow instructions using the labeled data.
RLHF ( Reinforcement Learning from Human Feedback )
- This is what we discussed on the LLM Understanding#How to reduce hallucinations?, as by showing the model to answer I don't know.
- Reinforce what good behavior is and what bad behavior is.
DPO (Direct Preference Optimization)
- Newer method of RLHF. You make the model choose between two outputs and then you train it to choose the better one. (this is why chatgpt asks you which preference you like better)
- More stable and less expensive than RLHF.
- well gets around the same results or better.
Transformer related Stuff
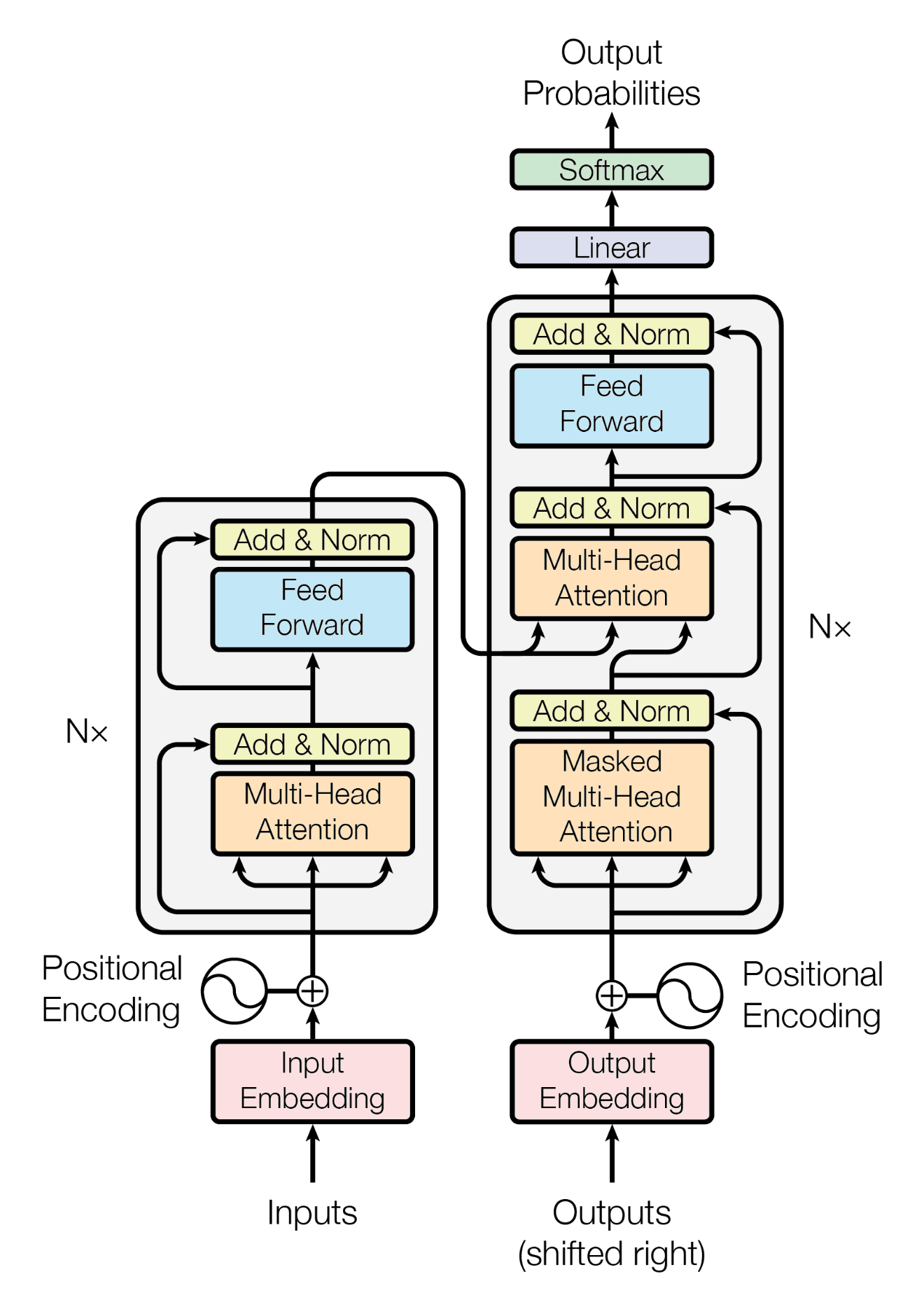
Self-Attention
Mathematical Expression for Self-Attention
The self-attention mechanism is like THE core of transformer models that power LLMs.
Where:
represents the queries represents the keys represents the values is the dimension of the keys (used for scaling) is the sequence length
The attention weights:
\begin{document}
\begin{tikzpicture}[scale=0.8]
\draw[->] (0,0) -- (4,0) node[right] {Token position (keys)};
\draw[->] (0,0) -- (0,4) node[above] {Token position (queries)};
\draw[very thin,color=gray] (0,0) grid (3,3);
\filldraw[fill=blue!20] (0,0) rectangle (1,1);
\filldraw[fill=blue!70] (1,0) rectangle (2,1);
\filldraw[fill=blue!30] (2,0) rectangle (3,1);
\filldraw[fill=blue!80] (0,1) rectangle (1,2);
\filldraw[fill=blue!10] (1,1) rectangle (2,2);
\filldraw[fill=blue!40] (2,1) rectangle (3,2);
\filldraw[fill=blue!20] (0,2) rectangle (1,3);
\filldraw[fill=blue!50] (1,2) rectangle (2,3);
\filldraw[fill=blue!90] (2,2) rectangle (3,3);
\node at (1.5,-0.5) {Attention Matrix};
\end{tikzpicture}
\end{document}
For multi-head attention, we have:
Where each head is computed as:
With learnable projection matrices:
The loss function for next-token prediction is typically cross-entropy:
Where:
is the number of tokens in the sequence is the vocabulary size is 1 if token is the -th word in the vocabulary, 0 otherwise is the predicted probability that token is the -th word
Sources
- Taken from Andrej Karapathy (the goat) deep dive into LLMs.
- LLM Architecture Visualization
- UltraChat Atlas.
